Lance Inimgba

Data science enthusiast who loves getting lost in Jupyter notebooks 😋
Love travel and foodie actvities!
View My LinkedIn Profile
Bank Loan Project

In this project, I will be assuming the role of a new hire on a bank they’ve asked me to fulfill these basic tasks as to get a feel from where I’m at:
- Return all rows of the table, but only the borrower & due to IDA column
- Only show the first 5 rows of the previous query
- Abbreviate one of the column names so it’s easier to write
- Show us all transactions from Nicaragua (the country)?
- How many total transactions?
- How many total transactions per country??
- What is the max owed to the IDA?
- What is the average service charge rate for a loan?
- Return all loans from the country of Honduras where the service charge rate is larger than 1
- Who has the most loans?
This project will be more of a walkthrough than anything else and at least prove (hopefully)that I have basic SQL skills if my other SQL projects don’t convey that too well.
Why This Project and What the data set is?
The reason why I personally chose this dataset is because I have a keen interest in the financial sector and it is one of the domains that I have the most curiosity in working in. So I thought it would be a good exercise in getting my feet wet and get used to some of the columns and common terminology that I could possibly be seeing in financial datasets. Plus, I thought that this would be a pretty good bit of a SQL flex as I spend most of my time in Python, I just thought that a little bit of a SQL wouldn’t hurt! 💪💪💪
Lastly, who doesn’t like learning about finances??
For this dataset, we are using data from the archives of the World Bank website. In case you haven’t heard of the World Bank before, they are an international financial institution that provides grants and loans to developing countries with the goal of creating sustainable development projects that will lead to more economic opportunities and the easing of poverty in said countries.
The actual dataset, IDA Statement Of Credits and Grants - Historical Data, is curated from the World Bank’s International Development Association or IDA for short. The IDA is a department of the World Bank that is responsible for helping the world’s poorest countries and provides low-interest to zero loans called “credits” along with grants to help fund projects that reduce inequalities and help improve living conditions. It also has a whopping 1.12 Million rows, so it gives us a sense of how large of a scale that the IDA is operating on.
The dataset contains historical snapshots including the most recent snapshots of the dataset.
Data Dictionary
There are 30 columns of data, but I will only go over the relevant ones that’ll be most crucial to our data analysis for this project:
- Borrower: The representative of the borrower to which the Bank loan is made.
- Country: Country to which loan has been issued. Loans to the IFC are included under the country “World”.
- Service Charge Rate: Current Interest rate or service charge applied to loan.
- Due to IDA: Amount currently owed to the IDA
Data Analysis
There isn’t much to explain here, but I’ll provide an explanation on the queries that require more explanation.
Return all rows of the table, but only the borrower & due to IDA column
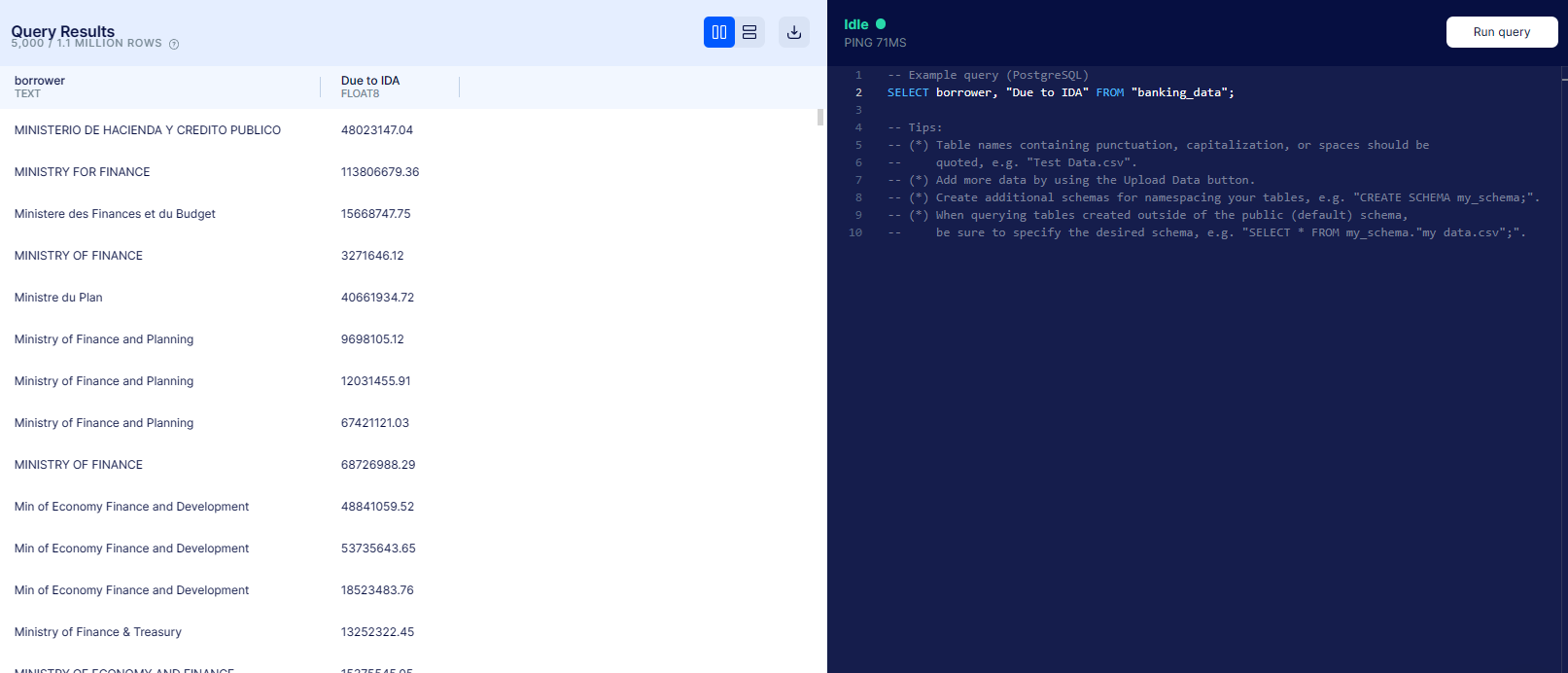
Table is outputted by `SELECT
Only show the first 5 rows of the previous query
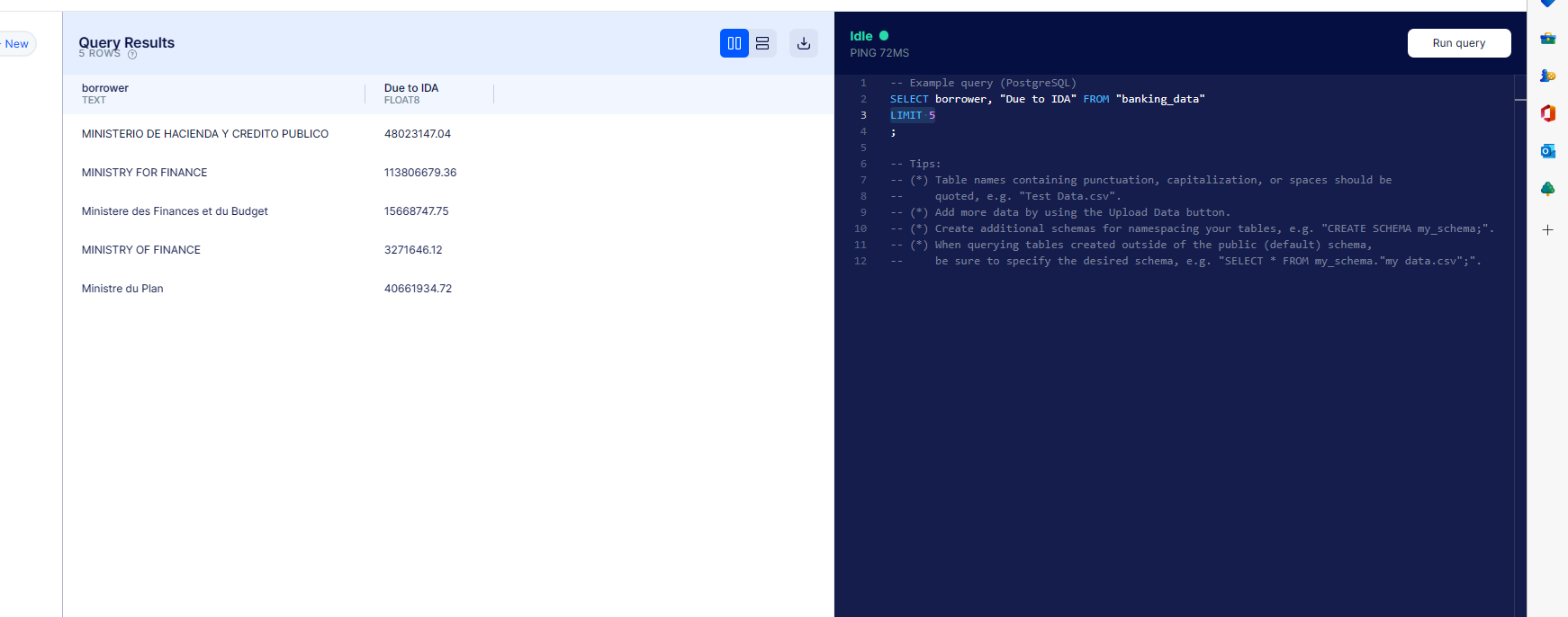
The LIMIT 5 portion on the query in the screenshot is what limits the output to only the first 5 rows.
Abbreviate one of the column names so it’s easier to write
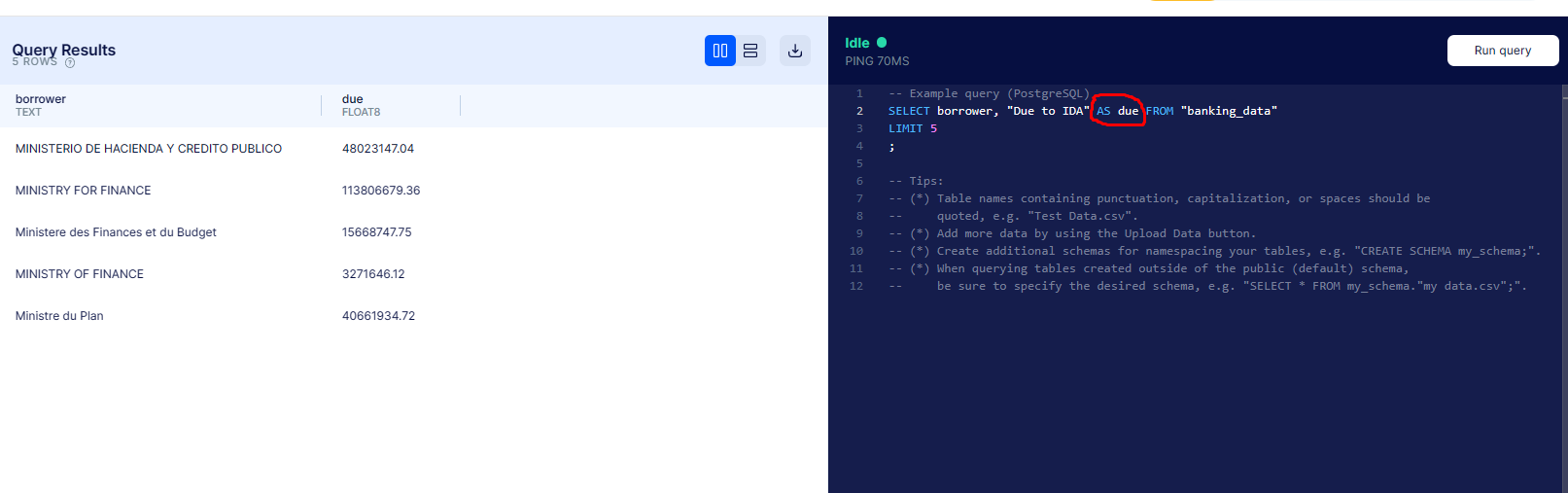 The standard way of creating an alias for a column
The standard way of creating an alias for a column
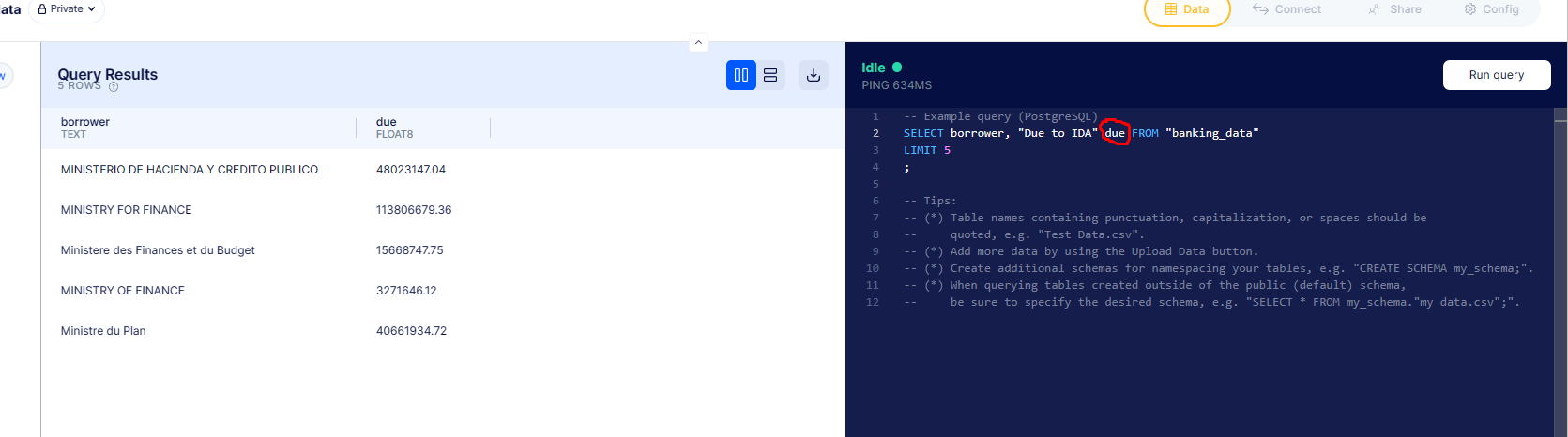 An alternative but slightly more congested approach to making an alias. It’s not bad in shorter and simpler queries though.
An alternative but slightly more congested approach to making an alias. It’s not bad in shorter and simpler queries though.
Show us all transactions from Nicaragua (the country)?
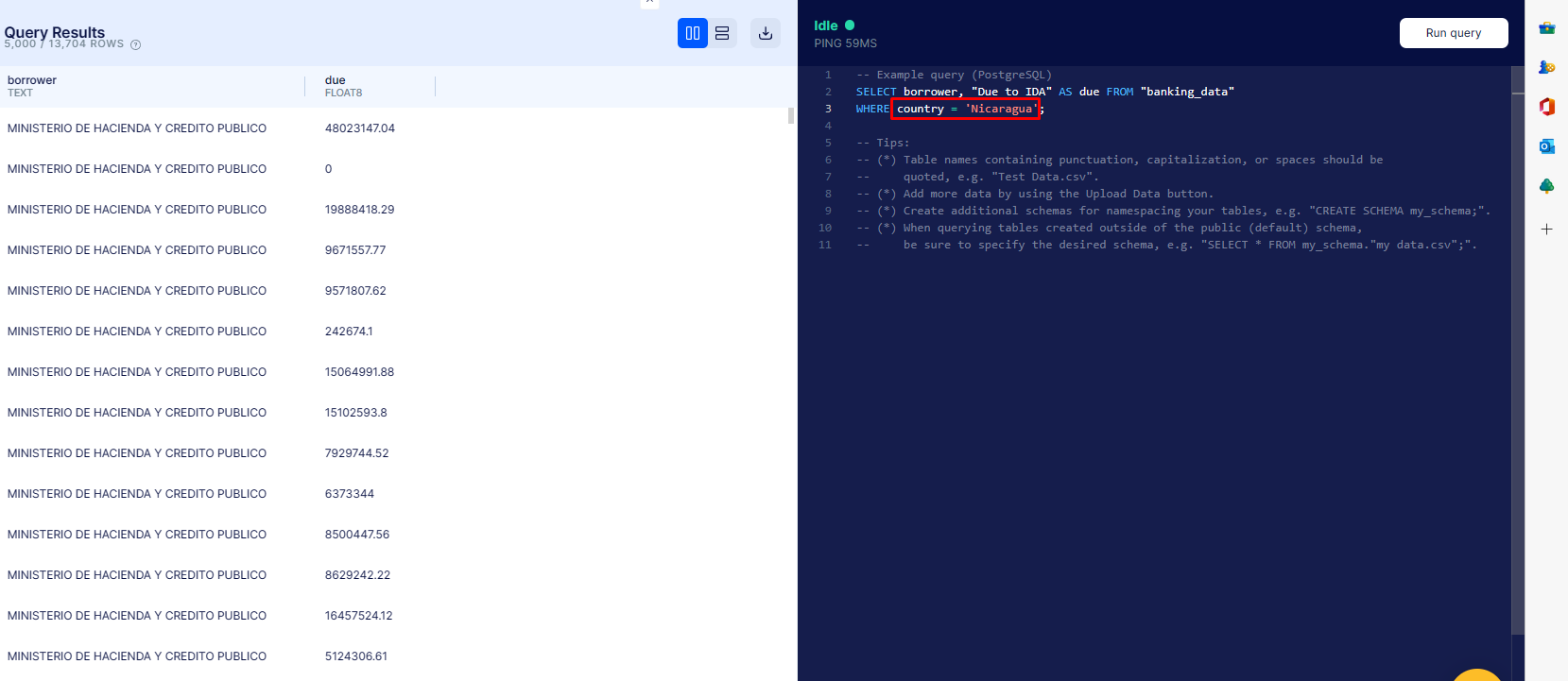 Accomplished by the
Accomplished by the WHERE = 'Nicaragua line
How many total transactions?
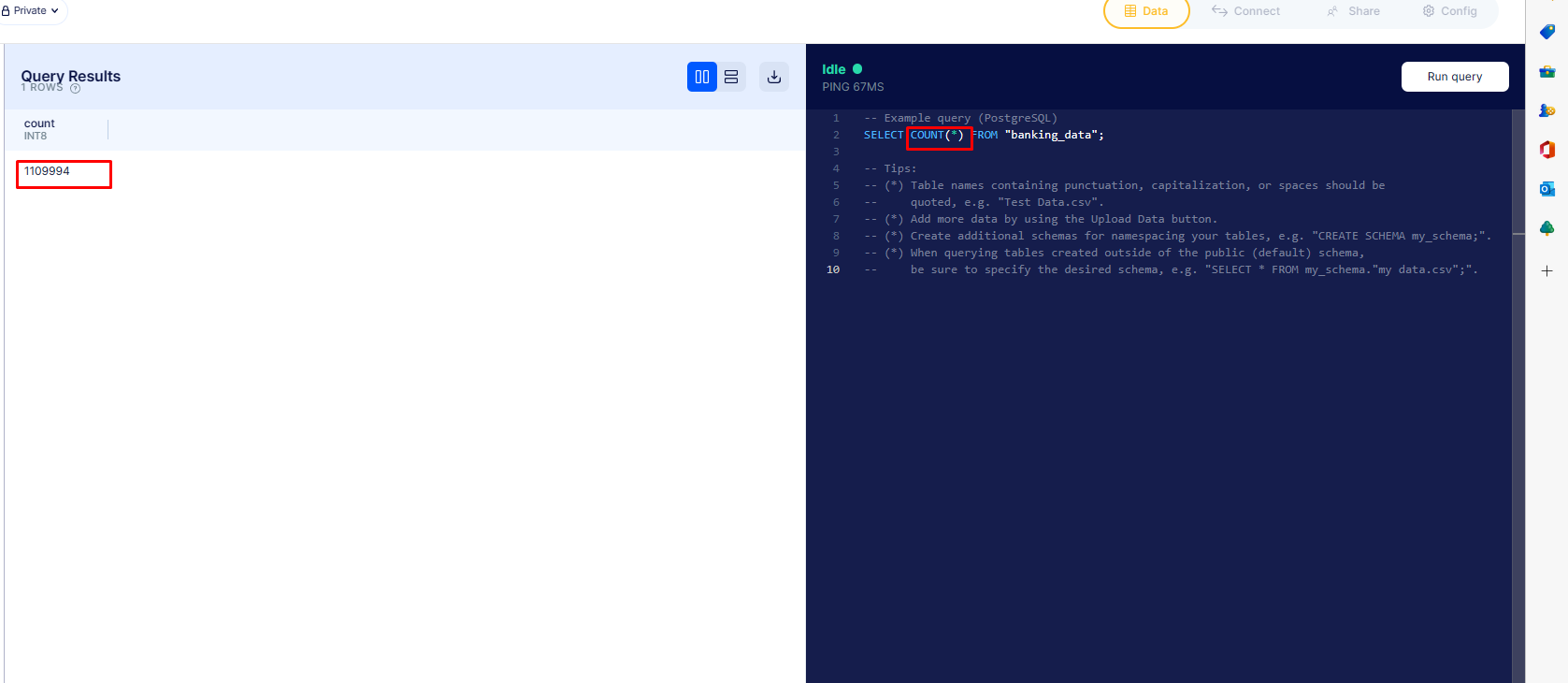 The
The COUNT function counts the amount of rows to give us this answer. Remember, that each row represents a single transaction.
How many total transactions per country?
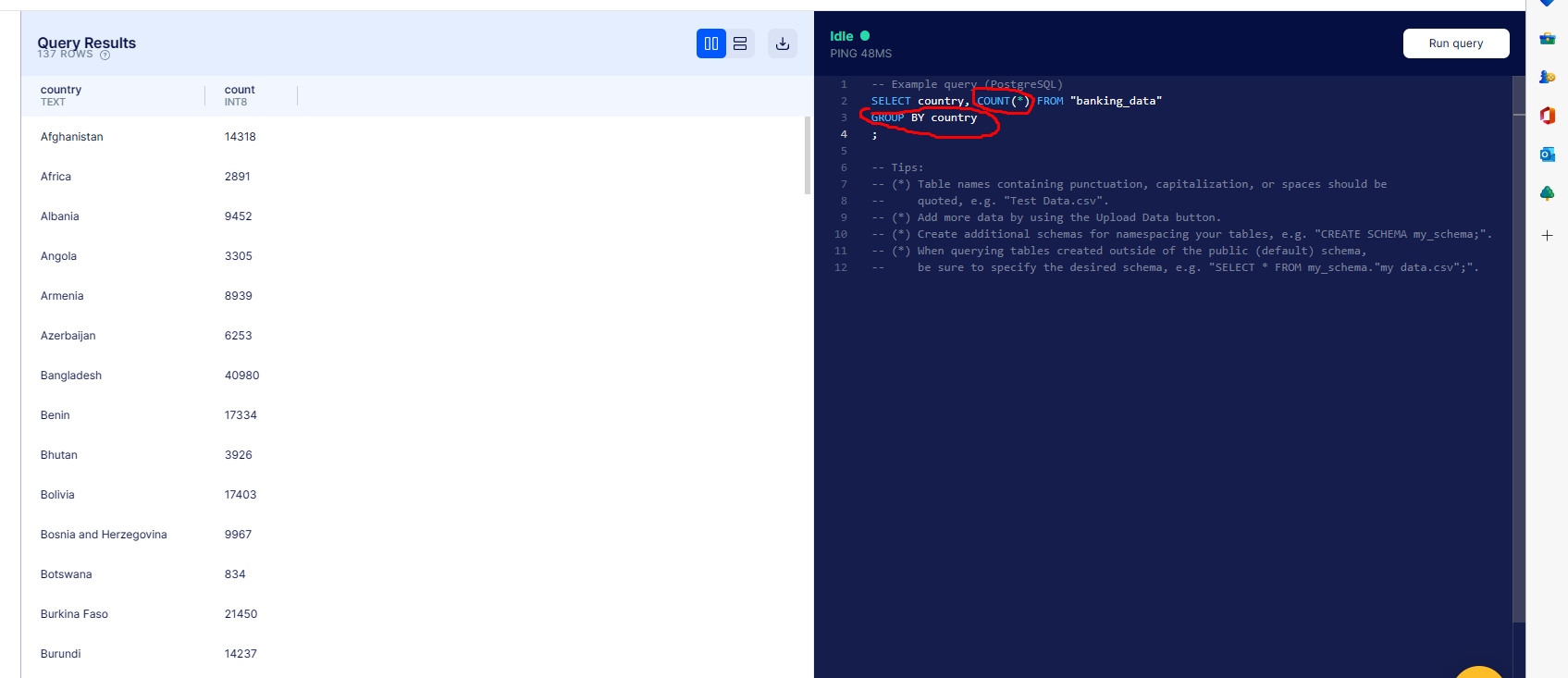 We use the
We use the COUNT function once again, but we also use GROUP BY country to ensure that we’re returning the number of transactions per country.
What is the max owed to the IDA?
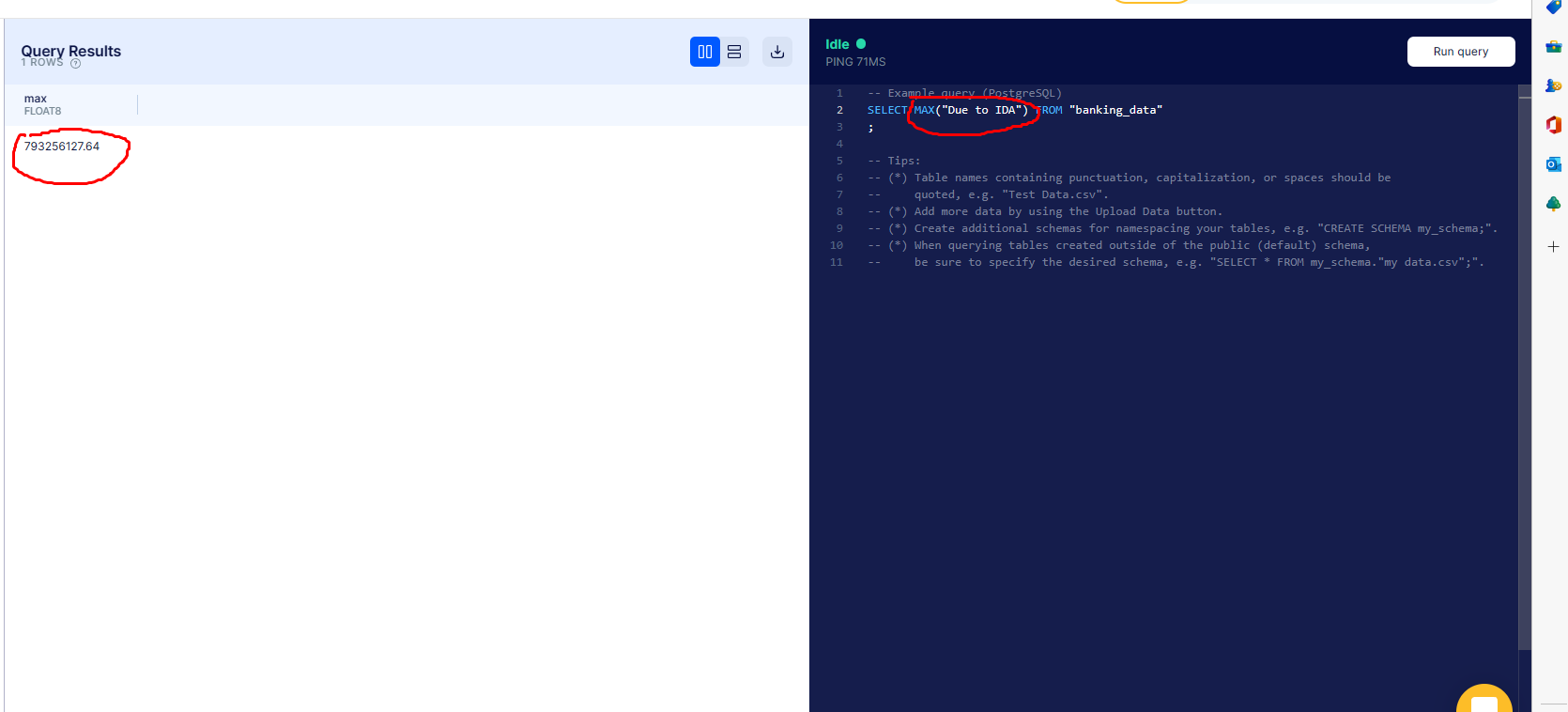 We use
We use MAX("Due to IDA") to get the maximum value that is owed to the IDA
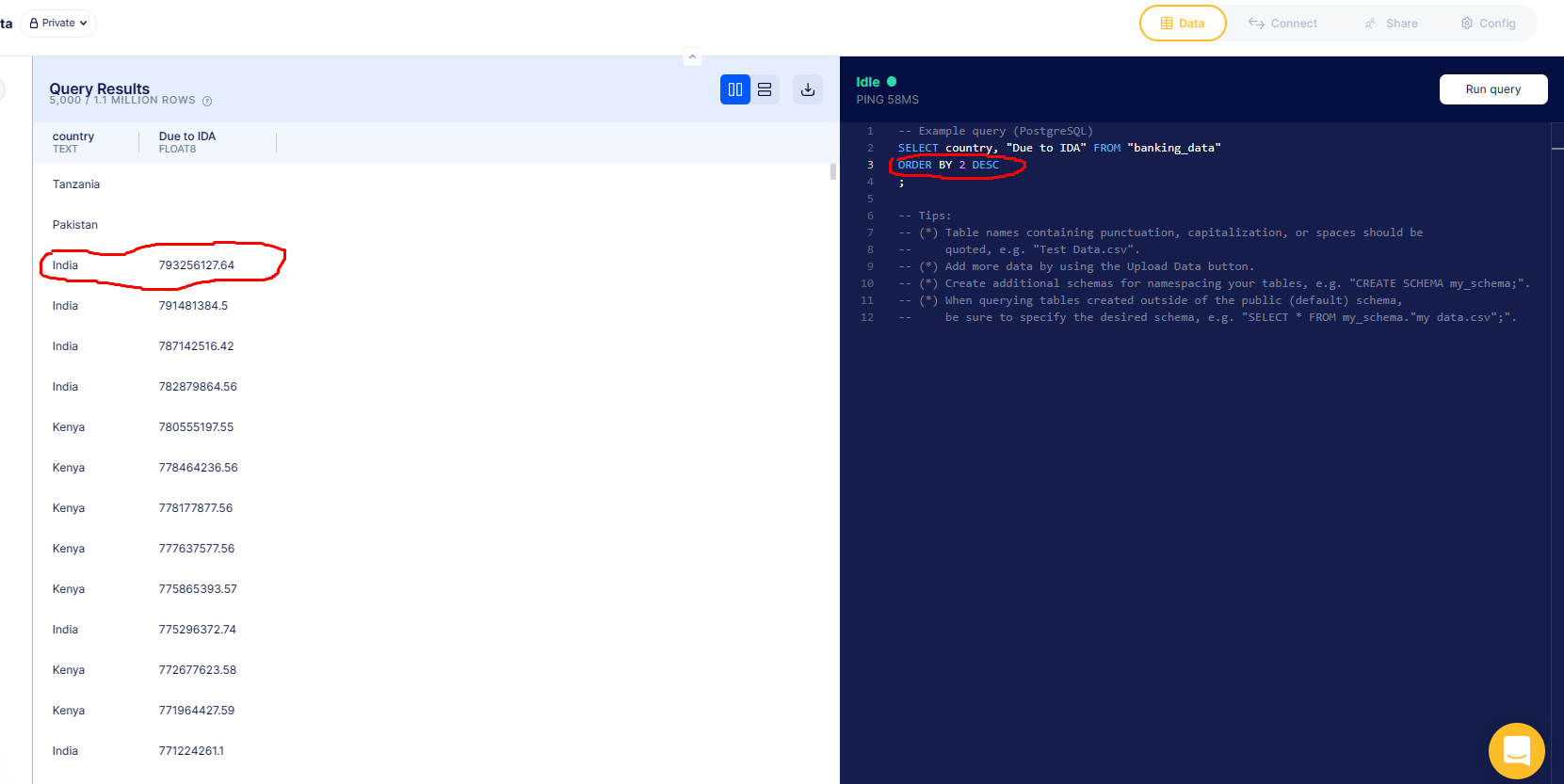 This is another way to do it and we can also find out the country’s name in this method.
This is another way to do it and we can also find out the country’s name in this method.
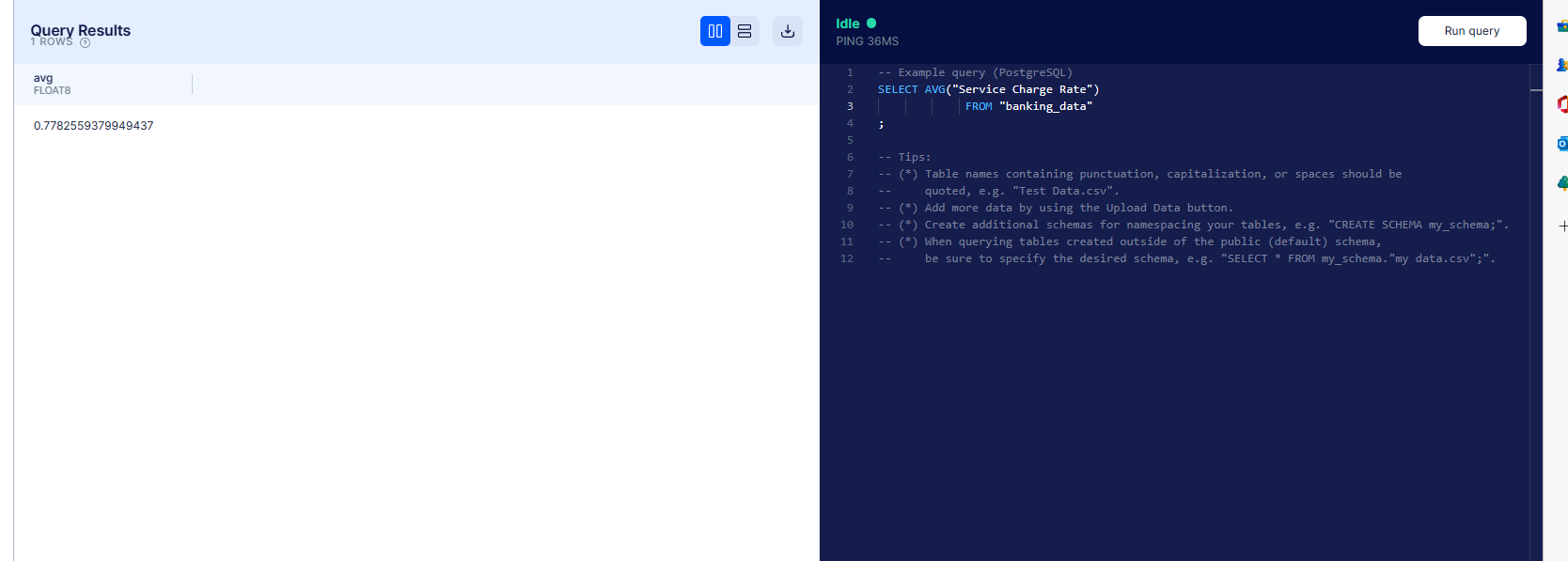
What is the average service charge rate for a loan?
 We use
We use AVG("Service Charge Rate") to get the very lengthy value of 0.7782559379949439.
So in the next screen I decided to round it to 2 decimal places
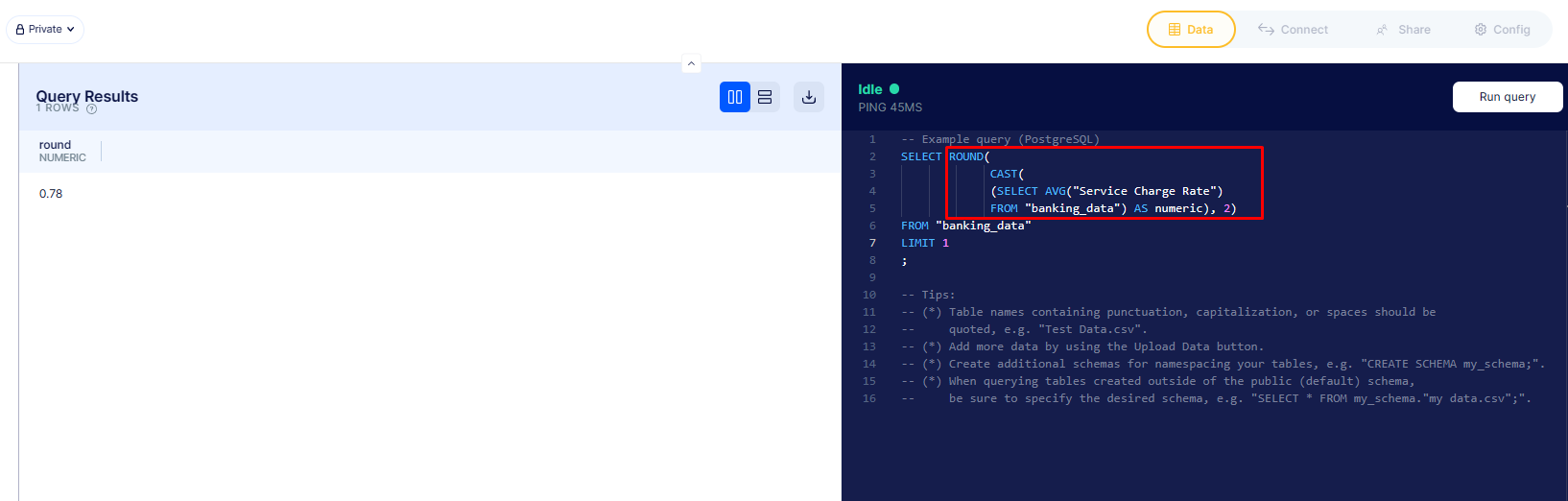 In this more complicated query, I have to find the
In this more complicated query, I have to find the AVG("Service Charge Rate") in a nested subquery before using a combination of CAST nested in ROUND to get our new rounded average. Note that in the outer query I use LIMIT 1 o or else it would have displayed 0.78 in every row.
Return all loans from the country of Honduras where the service charge rate is larger than 1
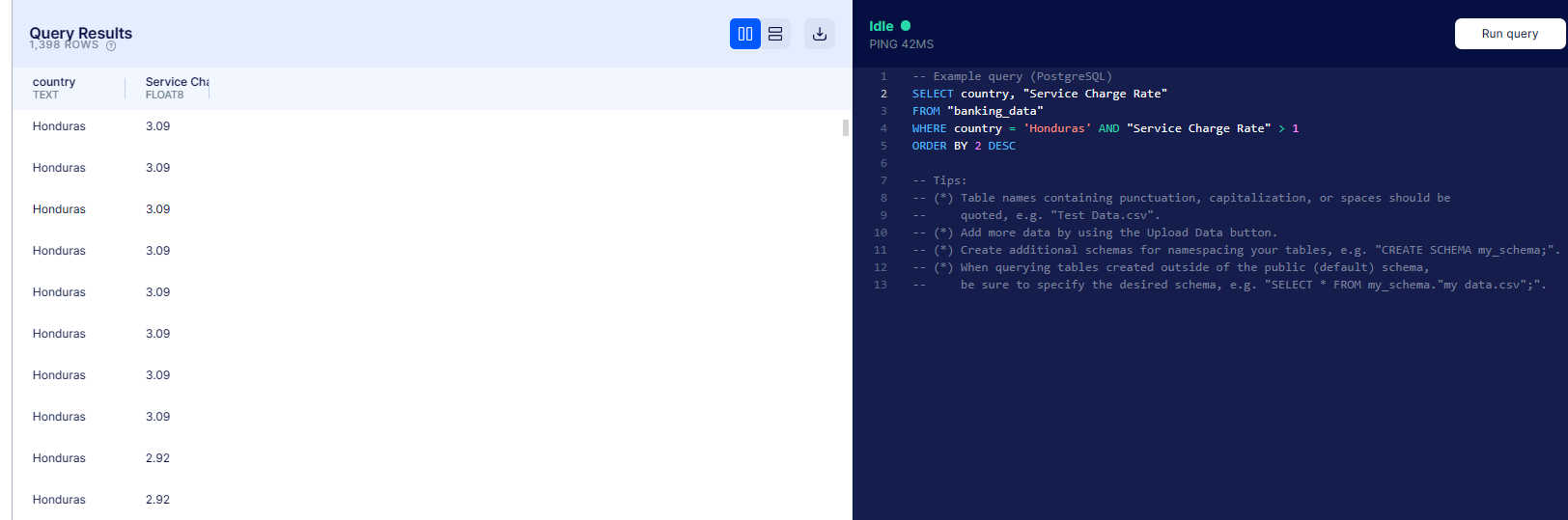 We use `WHERE = “Honduras” AND “Service Charge Rate” > 1 to filter out only the rows in which both conditions are true.
We use `WHERE = “Honduras” AND “Service Charge Rate” > 1 to filter out only the rows in which both conditions are true.
Who has the most loans?
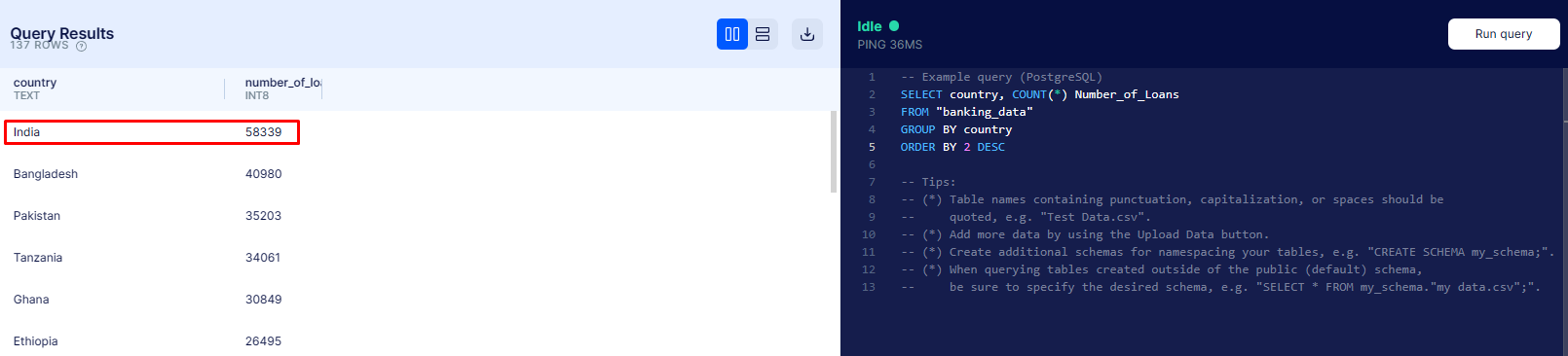 Using a combination of
Using a combination of COUNT, GROUP BY and ORDER BY, we managed to determine that India has the most loans.
Recap/Conclusion
As I specified in the beginning of this project, this was meant to be more of a walkthrough of basic SQL fundamentals than a super in-depth project. But in answering these questions:
- Return all rows of the table, but only the borrower & due to IDA column
- Only show the first 5 rows of the previous query
- Abbreviate one of the column names so it’s easier to write
- Show us all transactions from Nicaragua (the country)?
- How many total transactions?
- How many total transactions per country??
- What is the max owed to the IDA?
- What is the average service charge rate for a loan?
- Return all loans from the country of Honduras where the service charge rate is larger than 1
- Who has the most loans?
I feel like we’ve seen that SQL is more than capable of answering questions like these and even more complex questions, we definitely could. We would be able to do such things as group our information into the region column, answer questions such as which region has the most transactions/loans and use those findings to explore even more insights! In the future if I were to revisit this dataset, I would combine it with Python for getting rid of the nulls and dropping some rows (transactions) with a lot of null columns as I don’t think we lose too much, by dropping them
Thank you so much for your time and reading all of this! This was an absolute pleasure to do and if you have any questions, please comment below or please contact me at lance.inimgba@gmail.com or on LinkedIn!
I’m actively looking for new opportunities in the data science field, so please don’t hesitate to contact me if you know of anything out there!